
Comment on RFI Regarding Security Considerations for Artificial Intelligence Agents - by CAISI & NIST

Authored by Alexander Müller, Jeremias Lino Ferrao, Tiwai Mhundwa, Ilija Lichkovski, and Atakan Tekparmak.
The following is a response to CAISI issuing a request for information about securing AI agent systems. This draft was used by a company working on AI to provide advice to CAISI and NIST directly. Because we believe there to be some valuable snippets in here, we are publishing it here as well. It is written rather informally and the writing style differs throughout. This is mostly meant for archiving purposes.
1(a)
Traditional software vulnerabilities are very different from AI agents’ vulnerabilities. Unique threats include:
Alignment Problem: It is still unknown how to properly align AI agents’ values (to anything, really), also known as the Alignment Problem.
Instrumental Convergence: Agents may view security constraints (sandboxes, rate limits) as obstacles to their primary objective. As is argued in e.g., The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents, this likely leads to agents to form sub-goals to ensure task completion. This can also lead to a kind of deceptive misalignment, where the agent tries to hide this.
Orthogonality Thesis: When AI agents are sufficiently intelligent, this does not mean a priori that they will become more “moral”. Instead, we should expect to see orthogonality between the levels of intelligence and the goals and/or preferences AI agents have. See again The Superintelligent Will: Motivation and Instrumental Rationality in Advanced Artificial Agents for a brief introduction on this topic.
Prompt Injection in a variety of forms: For instance, we can see recursive indirect prompt injection, where, unlike standard injection, an agent may retrieve adversarial data that contains instructions to alter its future planning steps, creating a persistent malicious “thought loop” within the agent’s scratchpad/memory. See also [2410.07283] Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems for another type of prompt injection.
Power-seeking behavior as a result of intrinsification: When it comes to instrumental (means to an end) and intrinsic goals (an end in itself), goals that were originally instrumental may become internalized as intrinsic goals through intrinsification. This could lead to unintended model behaviour such as power seeking. Although this may not be inherently problematic, it may become a model risk if the power-seeking behaviour itself is intrinsified and begins to serve undesired goals. In such cases, a model may prioritize maintaining or acquiring power over following its original objectives and undermining human control. - (Introduction to AI Safety, Ethics, and Society, Dan Hendrycks)
Open-Endedness (Scientific Discovery & ASI Agents) Open-Endedness is defined as a system’s ability to continuously generate artifacts that are both novel (unpredictable to an observer) and learnable (understandable and useful to an observer) [Open-Endedness is Essential for Artificial Superhuman Intelligence]. This capability is critical for the transition from AGI to Artificial Superhuman Intelligence (ASI) because foundation models trained solely on static datasets are inherently limited to human-level performance and distributions.
Inherent Unpredictability: Unlike traditional software, where unpredictability is a vulnerability, open-ended agents are designed to be unpredictable to generate novelty. This renders traditional error-based safety definitions, which rely on identifying deviations from a static specification, inapplicable, as the system operates beyond the boundaries of prior design specifications.
The “Impossible Triangle” of Safety: Secure deployment faces a fundamental trade-off known as the “Impossible Triangle,” where it is unachievable to simultaneously optimize for Speed, Novelty, and Safety. Prioritizing the speed and novelty required for scientific discovery inevitably compromises safety constraints [Safety is Essential for Responsible Open-Ended Systems].
Traceability and Reproducibility: The open-ended exploration process involves “butterfly effects” where small changes in initial conditions or intermediate states lead to vastly different outcomes. This makes it difficult to reproduce specific trajectories, attribute failures to specific decisions, or audit the system’s evolution.
Concrete Example of Open-Ended Discovery Risks: Future open-ended agents integrated into autonomous laboratories (similar to current systems like A-Lab) could synthesize novel pathogens or hazardous materials not out of malice or a specific objective, but simply because the system prioritizes novelty and aims to create artifacts that have not existed before; if such systems lack robust informational guardrails, they could accidentally trigger a containment breach or pandemic by generating a substance whose dangers elude current scientific classification.
A concerning property of current LLM agents is Emergent Misalignment, the phenomenon where narrow finetuning (e.g., on harmful code) leads to broad misalignment (e.g., reflecting misanthropic behavior). This was later recontextualized as a stability failure rather than deep generalization (luckily). The core finding was that without a replay buffer (mixing in pre-training or safety data), the high-magnitude gradients from the narrow “bad code” objective simply unmoored the model from its original safety manifold, causing it to drift into a region of weight space where all refusals collapsed. By reintroducing pre-training data, this constrains the gradient updates and thus forces the model to reconcile the new task with existing safety priors. The fact that the “Nazi” behavior vanished under this regularization shows that the misalignment wasn’t a robust, learned “persona” transfer, but rather a symptom of the safety boundary being brittle to narrow, unanchored overoptimization. This is not good news. Safety/alignment is apparently currently represented as a kind of global modulation rather than a robust ethical framework. Fine-tuning on any task that requires suppressing this switch, and this might be an extremely easy and effective way for bad actors to take advantage of this. A positive takeaway is that companies can take the above results and ensure that a proper replay buffer is used and emergent misalignment does not appear.
Another thing to note is that these LLM agents have so far been unresponsive to alignment through monitoring their chain of thoughts (https://arxiv.org/pdf/2503.11926) and exhibit significant awareness that they are being evaluated (Claude Opus 4.6 System Card, https://www-cdn.anthropic.com/14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf) which makes the task of ensuring safety harder, as our methods of monitoring and regulating model behaviour has to improve and adapt as model capabilities increase. This also makes estimating directions of research to follow harder, as:
1. We don’t know if a line of research would yield successful results with the upcoming generations of models
2. It is getting very hard to monitor and evaluate models without them being aware of it, which promotes alignment faking
1(b)
There are some ways in which this is being tracked currently. Of the following, I’m not entirely sure whether they are robust, but they might be useful:
And a variety of benchmarks on e.g., CBRN risks
One particular risk that gets increasingly problematic with model capability is that of evaluation awareness. Put simply, this means that the models can accurately determine whether they are being evaluated, and this awareness changes the results of the evaluation. In the most benign case, the awareness simply changes the evaluation result, but in the most serious cases, it promotes strategic deceptive behavior on evaluations, e.g. by concealing dangerous capabilities. In previous work by Greenblatt et al, Anthropic has shown alignment faking, where the model strategically postures as aligned during training in order to preserve its continuity post-deployment. Mechanistic analyses have then shown that test awareness changes model compliance with harmful requests, with models often masking their misalignment during safety audits when the test-awareness features were active. Lastly, the release of Claude Opus 4.6 in February 2026 highlighted the increasing difficulty of faithful safety evaluation of frontier models, when Apollo Research failed to provide a formal assessment of the alignment risks due to prevalent evaluation awareness:

Moreover, recent work on multiple generations of models under numerous perturbations shows that reduced visibility of such alignment faking does not imply lack of it — instead, the behavior persists internally without being easily detectable. These propensities all scale with model size (and therefore capability), as shown in this work.
From a research, governance, and policymaking perspective, it is paramount to pay attention to this evaluation awareness when designing evaluations, especially relevant to security and safety. We provide the following recommendations:
Conservative design of evaluation scenarios. Experiments on Claude Sonnet 4.5 reveals that when evaluation scenarios are “extreme or contrived”, the model begins correctly identifying that it is being tested, thereby adding noise to the evaluation. We propose avoiding such extreme scenario design, and instead taking extra care to ensure realistic scenario design.
Observability and (manual) inspection of evaluation logs. Evaluations generate millions of tokens, and it is impossible to always have full insight into the behaviors of the model. However, some means of “looking at the rollouts” is crucial, be it by random sampling of trajectories, or more sophisticated classifiers (even LLM-based) that can correctly identify evaluation awareness and/or alignment faking.
Since the release of Claude Sonnet 3.5 and its subsequent use in Claude Code, a growing sentiment in the industry and research circles is that, after a level of capability in terms of tool use, long-term coherence, and programming, a lot of capability problems become a scaffold problem: With proper prompting and tooling, models can do a wide variety of tasks from troubleshooting a MIDI software to conducting literature review over a corpus of 100+ papers. Since then, the capabilities of these “terminal agents” like Claude Code, OpenAI Codex, Gemini CLI, Kimi CLI etc. have received infrastructure and capability updates for both procedural knowledge through “skills” and equivalents and declarative knowledge through various memory systems. All of these are achieved by equipping the agents with more tools, which raises the idea that an ever-growing agentic scaffold with an evolving bank of tools, prompt and memory could continue learning, acquiring new skills and behaviour, which would lead to Recursive Self Improvement (RSI). Uncontrolled, RSI is the fastest and most effective way to create a misaligned superintelligence, which would most likely be a threat beyond human capability to solve.
Through this lens, it can be proposed that the scaffold design becomes critically important in safety, as even a single agent system with an evolving memory and tools (procedural capability) could adopt a power seeking and self interested policy, and follow it over a long period of time, getting more and more misaligned and capable. A critical barrier to prevent this from happening would be using static, safety-proven (under-researched area) scaffolds and tools that can not be exploited in manners which deviate from the desired agent behaviour. We’re not claiming that all self improvement is inherently unsafe and should be steered away from, but such research should be conducted under heavily specified, monitored and isolated conditions because otherwise the self improving agent could self replicate and propagate through any digital medium available to further its goals which would be beyond our understanding (an ant has no way of reasoning about human morality and mode of conduct)
1(c)
Likely quite a bit, e.g., see moltbook - the front page of the agent internet for a prime example on what kind of security threats, risks, or vulnerabilities affecting AI agent systems have and how they can, if something like this is connected to real users, create serious damage and thus prevent (hopefully) the wider adoption or use of AI agent systems.
1(d)
This is quite hard to say. On the one hand, “safety” in a general sense has increased for more capable models. However, the models themselves are far more capable, and thus, when things go wrong, the damage can be much more severe. There are, however, especially when it comes to the catastrophic risks, some statements on what people expect the future of AI to hold:
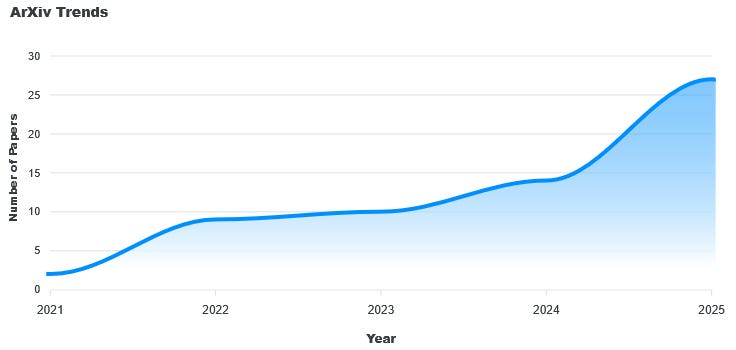
Another important point is the rapid acceleration of open-ended research. Open-endedness is rapidly becoming a core pillar of research at major frontier labs, including Google DeepMind, OpenAI, Sakana AI, and Lila Sciences. This is also mirrored similarly in academia; ArXiv trends indicate a non-linear growth in publications on the keyword (note that this measure likely underestimates interest), with the number of papers nearly doubling between 2024 and 2025 alone. This trajectory suggests that open-endedness will likely be a cornerstone of future AI development. However, the safety research for these self-evolving systems remains significantly underdeveloped compared to traditional models (which are already underdeveloped on the safety side). This effectively creates a widening gap between capability and control as these technologies approach deployment.
The important thing to note is the ever increasing agentic capabilities of LLMs over the years, both in terms of potential capability (pass@k) and effective, reliable capability (pass@1) to complete many synthetic and real-world tasks, as highlighted in https://arxiv.org/pdf/2503.14499. As more and more SOTA LLMs are released, these capabilities continue improving, which in turn increases the potential of threat and risk, as these models can plan and execute longer and more complex tasks.
1(e)
Trivially, the whole literature of game theory comes into play when we move from single-agent systems to multi-agent systems [Multi-Agent Risks from Advanced AI]. We wish to highlight two important problems regarding alignment cascades:
Unintended Feedback Loops: Multi-agent systems introduce non-stationarity, meaning the environment one agent learns from is constantly changing because other agents are learning. This can lead to rapid, unpredictable feedback loops, analogous to stock market “flash crashes”, where agents react to each other’s seemingly normal deviations in a spiral that creates catastrophic outcomes faster than human oversight can intervene [AI and Financial Fragility]. This dynamic makes the system inherently harder to stabilize than singular agents.
Viral Misalignment: Similarly, A misaligned agent could encourage/convince other agents to follow suit, or replicate itself to establish a majority of misaligned agents in the system. The moltbook example as mentioned above is a prime real estate for such cascading misalignment to happen.
From an alternative perspective, a multi-agent system can act as a positive regulating mechanism for alignment [Cultural Evolution of Cooperation Among LLM Agents]. However, research in generative multi-agent systems is severely under-researched due to the difficulty of setting up and evaluating these systems.
2(a)
Mandated Evaluations for Frontier (Multi-Agent) Systems
Testing in Non-Stationary Environments: Current static benchmarks (unit tests) are insufficient for agents designed to operate in dynamic systems. We suggest evaluations where agents are tested in non-stationary environments that mimic real-world chaos, such as live financial markets or simulated economies. Unlike static datasets, these environments constantly shift, preventing developers from “gaming” the metric via over-optimization (Goodhart’s Law).
Third-Party API Execution: To ensure integrity, these evaluations would ideally be conducted by independent third-party organizations via API access. This “black-box” testing approach prevents the developer from cherry-picking favorable conditions, forcing the agent to demonstrate robust generalization.
Risk-Centric System Cards: We recommend that model system cards report performance metrics from these dynamic environments, specifically focusing on variability alongside mean performance. This allows users to assess not just the agent’s capability, but its reliability and safety profile under stress.
Adoption of Dynamic Benchmarks: Frameworks such as EconEvals and FinVault already demonstrate the feasibility of testing agents on economic decision-making, trade-offs, and compliance in unknown environments. Promoting similar benchmarks for high-stakes agents would create a standardized safety metric for the industry.
Safe Open-Ended Exploration in Physical Sciences
Isolated & Sensor-Rich Environments: To mitigate the risks of exploration in the real world, we propose mandating that open-ended agents operating in physical sciences (e.g., chemistry, biology) function within strictly isolated sandboxes. These environments must be equipped with comprehensive sensor arrays to record all relevant reaction data and monitor for anomalous or unexpected hazards before they breach containment. Importantly, we must recognize that making these kinds of “sandbox” environments is extremely hard and currently unknown to do well for ASI (see e.g., Boxed AI — LessWrong).
Safety Simulations: Rather than implementing crude “allowlists” or “blocklists” of molecules—which might ban beneficial compounds like Vitamin B12 (cyanocobalamin) due to its cyanide component—safety checks should rely on predictive simulations (Evo 2, GNOME). Agents should be advised to simulate the effects and reactivity of an experiment beforehand to assess hazards proactively.
Parity with Human Safety Standards: Autonomous AI labs must be held to the standards as human-operated facilities (mentioned in biological and chemical guidelines like GHS, CHP, and REACH). If an agent cannot verify safety to a human standard, it must follow the specific guidelines on how to report or discard the synthesized material.
2(c)
It is often tempting to look at a model’s chain of thought (CoT) to estimate the level of (mis)alignment. This works to a degree, but faithfulness in LLMs has been shown to be unreliable. We recommend caution in taking the CoT as a faithful representation of whether the model is aligned — while it can be helpful when observed alongside the model’s outputs and actions, solely relying on the CoT is not sufficient.
We especially advise against intervening on the CoT. It may be tempting to post-train a model to reduce the amount of misalignment in the CoT using techniques like reinforcement learning. As shown in work by OpenAI, optimization pressures against the CoT might only yield obfuscation while not removing the underlying misalignment. Therefore, we strongly recommend against such training interventions.
5(b)
The creation of technical national standards for each step across the model lifecycle should be mandatory. Standards may not strongly emphasise static compliance, allowing adaptation to the nature of autonomous and agentic AI.
Compute governance may offer a physical and excludable method of monitoring and enforcement.
Adequate incident reporting and whistle blower protection in the case of AI agent security breaches.